





Содержание
Различные последствия отключения электричества поможет устранить облачный Disaster Recovery (DR). Из статьи можно узнать, кто и как сможет использовать DR в различных аварийных ситуациях, какие существуют технические решения такой системы, кому они подходят и как установить такое аварийное восстановление. Представленная информация позволит владельцам бизнесов, получающих прибыль в онлайне, застраховаться от крупных убытков, возникающих в результате потери данных из-за аварийного отключения.
Disaster Recovery: широкие возможности для восстановления системы после аварийного отключения
Disaster Recovery (DR) это облачный комплекс инструментов для аварийного восстановления всех данных и инфраструктуры дата-центров после разнообразных крупных сбоев в сети в результате отключения электричества, пожара, наводнения, техногенной катастрофы, землетрясения, рядового сетевого сбоя или других причин, приводящих к потере важных данных и повреждению инфраструктуры.
Являясь резервной площадкой, используемой для оперативного восстановления точной копии сетевой инфраструктуры компании, DR способна в короткий период восстановить всю важную информацию дата-центра даже в случае ее полного уничтожения. При этом для создания такой системы аварийного восстановления не потребуется делать крупных затрат на оборудование, персонал и оплату электроэнергии.
Для того чтобы использовать весь потенциал облачной Disaster Recovery, необходимо выполнить ряд требований:
- организовать ее в географической удаленности от основной инфраструктуры;
- обеспечить высокоскоростную связь основного дата-центра с резервной площадкой, создав канал с максимально высокой пропускной способностью.
Выполнение такого набора требований позволит получить точную копию инфраструктуры, позволяющую полностью восстановить утраченную информацию в случае ЧС в основном дата-центре.
Варианты организации работы Disaster Recovery
Реализовать концепцию Disaster Recovery на физических носителях можно разными способами, требующими внушительных затрат. Ее можно сделать своими силами на базе собственной инфраструктуры, создав ее точную копию.
Самостоятельное создание требует привлечения высококлассных специалистов со стороны, хорошо разбирающихся в архитектурах инфраструктуры и обучении персонала. Для создания запасной копии нужно будет закупить дорогостоящие сервера и регулярно оплачивать расходы на электричество.
Также можно создать Disaster Recovery на арендованных физических серверах, полностью продублировав свою инфраструктуру в отдаленной географической точке. Для реализации обоих вариантов кроме крупных финансовых инвестиций потребуется немало времени.
Альтернативой дублю на физических носителях является облачный Disaster Recovery. Такую инфраструктуру легче создавать и форматировать. При использовании Terraform или других инструментов IaC-подхода можно создать дублирующую площадку в облаке в течение нескольких минут. Платить за облачный DR нужно только по системе pay-as-you-go, или по-простому только за потребленный ресурс, необходимый для поддержки облака. Если компания не использует созданный Disaster Recovery в течение года, она может существенно сэкономить на облачном дубле.
Преимущества готового облачного Disaster Recovery
Не обязательно облачный резервный DR создавать самостоятельно. Можно воспользоваться услугами готового сервиса Disaster Recovery. Он упростит многие технические процессы за счет перехода на OPEX-модель, облегчит поиск и настройки инфраструктуры. Клиенты, использующие сервис Disaster Recovery, получают дополнительные услуги, круглосуточную техническую поддержку, SLA и защиту от DDoS-атак.
Основные характеристики DR
Для работы Disaster Recovery важную роль играют две метрики аварийного восстановления —RPO (Recovery Point Objective) и RTO (Recovery Time Objective). С учетом их значения, а также реальных потребностей бизнеса для клиента провайдер подбирает то или иное техническое решение.
RECOVERY TIME OBJECTIVE
RTO – это время вынужденного прекращения работы, необходимое для восстановления инфраструктуры. Чем меньше для этого нужно времени, тем дороже обойдется аварийное восстановление для бизнеса. Это связано с тем, что для восстановления инфраструктуры в этом случае используются самые дорогие технические решения. Такие затраты на RTO необходимы банкам, приложениям, сервисам заказа еды, и другим компаниям, получающим прибыль от работы в онлайне.
RECOVERY POINT OBJECTIVE
От показателя RPO зависит максимальный размер данных, которые компания может потерять во время аварийного отключения без критических последствий для бизнеса. От величины данного показателя зависит количество и частота создания резервных копий: чем он меньше, тем чаще придется копировать важные данные. Это сказывается на конечной стоимости Disaster Recovery. Значение RPO всегда зависит от конкретных нужд компании. От значения данной метрики зависят допустимые объемы утраченных в результате аварийного отключения данных. Так, на SaaS-платформах, фиксирующих действия пользователей, обновление баз данных происходит через несколько секунд. Для сайтов это не настолько важно, поэтому обновлять информацию для аварийного отключения нужно не так часто.
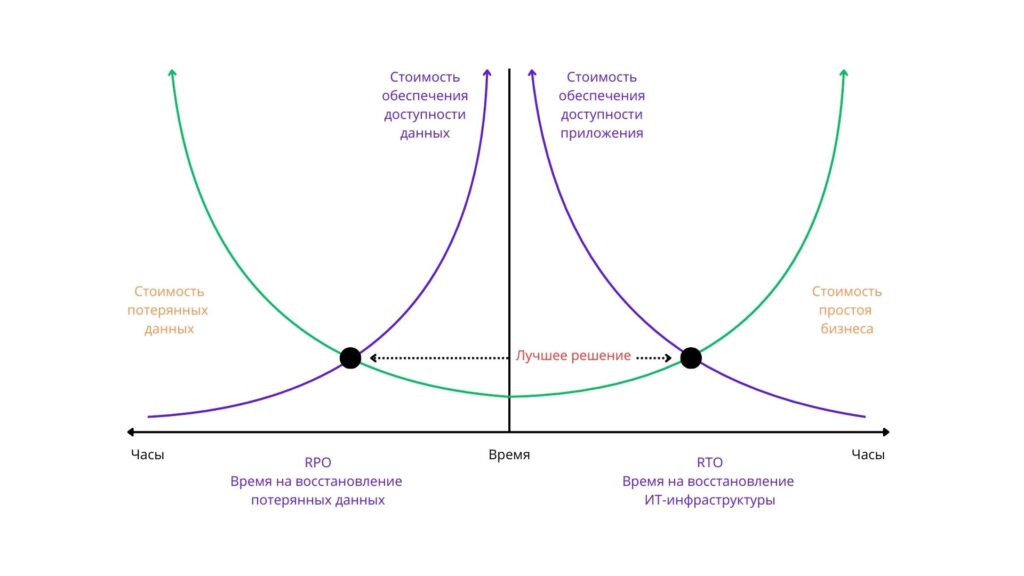
Как сделать правильный выбор?
Для правильного определения значений RPO и RTO нужно исходить из конкретных потребностей компании и правильно оценить существующие риски аварийного отключения. Для этого следует ответить на ряд вопросов:
- с какой регулярностью происходит обновление данных на сервере;
- какое количество пользователей у сервиса, приложения или сайта;
- какое количество денег в час или в минуту бизнес теряет во время аварийного простоя;
- насколько убытки могут быть больше расходов на создание Disaster Recovery.
Объективные ответы помогут в оценке реальных рисков и правильно составить баланс расходов на установку Disaster Recovery.
Определение показателей RTO и RPO – это часть плана аварийного восстановления IT-систем (Disaster Recovery Plan, DRP). Такой план должен быть у любой компании — вне зависимости от масштаба и специфики бизнеса.
Кто может воспользоваться Disaster Recovery?
Аварийное восстановление необходимо компаниям, где репутационные и финансовые потери при простое сервисов недопустимы. Прежде всего Disaster Recovery в облаке необходимы крупным банкам, платежным сервисам, службе по доставке еды и другим компаниям, работающим с клиентами через интернет в режиме 24/7 в течение всего года.
Облачный Disaster Recovery прост в настройке, для его установки не потребуется проводить экспертизу. Его можно развернуть в случае необходимости за 15 минут, при условии наличия инфраструктуры в облаке VMware любого типа. Можно использовать частное облако на своей или провайдерской инфраструктуре.
Расходы на Disaster Recovery окупятся с лихвой. Для компаний, не зависящих от бесперебойного доступа пользователей к их площадкам в сети достаточно использовать бэкапы, или резервные копии вместо аварийного восстановления инфраструктуры. При локальной аварии систему можно будет развернуть из бэкапа на новой инфраструктуре. В облаке это можно сделать достаточно быстро при наличии двух или одного серверов. Для восстановления всей инфраструктуры потребуется много часов, что чревато крупными убытками. Резервное копирование данных обязательно для Disaster Recovery, но она не является единственной составляющей.
Инструкция по самовоспроизведению облачной инфраструктуры
Для создания аварийного восстановления инфраструктуры следует выполнить ряд последовательных шагов:
- определить, какие проекты или сервисы нужно «продублировать» в облако;
- выбрать провайдера, учитывая, где расположены дата-центры, на какие ресурсы в облаке можно рассчитывать, какая пропускная способность каналов связи и производительность инфраструктуры;
- найти техническое решение по организации Disaster Recovery с разными значениями RTO и RPO;
- создать план аварийного восстановления (DRP), прописав алгоритм действий в случае аварии;
- преднастроить сетевую инфраструктуру, NAT, межсетевые экраны;
- настроить техническое решение и DR для сервисов;
- протестировать работоспособность системы;
- установить периодичность тестирования DR.
Как правильно начать работать с DR?
При использовании Disaster Recovery необязательно копировать всю информацию. В облако можно отправить самые важные данные или самые прибыльные проекты, зависящие от стабильного интернет-соединения. Некритичные сервисы или внутренние службы можно исключить, если они не выполняют важные функции для бизнеса.
После этого можно переходить к выбору провайдера. Основными критериям должны быть:
- географическая удаленность его дата-центров от вашей инфраструктуры;
- объем ресурсов в облаке;
- пропускная способность используемого соединения;
- производительность инфраструктуры;
- цена услуги;
- наличие бесплатного тестирования и других дополнительных услуг;
- соблюдение необходимых требований по информационной безопасности.
Когда определились с провайдером, можно выбирать техническое решение для организации DR с определенными значениями RTO и PRO. Все провайдеры предлагают своим клиентам несколько вариантов технических решений. После этого проводится преднастройка сетевой инфраструктуры, межсетевых экранов, NAT.
Когда настройка завершена, проводится тестирование системы, сымитировав аварийное отключение площадки от сети. Во время теста можно выявить слабые места DRP и уточнить время, необходимое для аварийного восстановления инфраструктуры. Для бесперебойной работы Disaster Recovery нужно сделать тестирование регулярным, задав определенную периодичность таких проверок.
Установка Disaster Recovery является крайней, но необходимой мерой. Может случиться так, что пользоваться таким аварийным восстановлением не придется в течении длительного времени. При этом гарантируется, что при аварийном отключении критически важных для бизнеса элементов инфраструктуры, работа компании не остановится, а восстановление всей инфраструктуры организации не займет много времени.









